Analyzing 9 million healthcare insurance claims with MotherDuck and Hashboard


We’re excited to announce the Hashboard integration with MotherDuck and give a quick walkthrough of how it helps Hashboard build on our DuckDB use cases and examples. We love using DuckDB for our demos and MotherDuck has made the developer experience much better (and helps us scale our DuckDB use cases to much more data).
Generating millions of synthetic patient records
All our demo datasets are pretty small since Hashboard’s file upload limit is 50 megabytes. We could connect Snowflake or BigQuery, but try to stick to DuckDB for our demos since they are lighter weight and easier to test.
Hashboard has a public Healthcare example where you can analyze a few thousand synthetic patient claims data and procedures. This is pretty limited, though.
At Flatiron Health, where some of our team previously worked, we were managing millions of patients in a single warehouse. Naturally we wondered if we could use DuckDB for a more production-sized demo. Could we conceivably use DuckDB in prod?
Enter MotherDuck! We updated our healthcare claims demo to generate millions of patients of data. You can check out the branch / code here.
cd healthcare_claims
python generate_claims.py
# generates a couple hundred megabytes of synthetic healthcare claims data:
claims.parquet
claim_details.parquet
patients.parquetGet the data into MotherDuck
You can login to MotherDuck and upload the three generated parquet files to the web client. You can then run the following commands to load the data into MotherDuck. Loading the data will take a couple of minutes since there is close to a gigabyte of data here.
CREATE OR REPLACE TABLE patients AS SELECT * FROM read_parquet(['patients.parquet']);
CREATE OR REPLACE TABLE claims AS SELECT * FROM read_parquet(['claims.parquet']);
CREATE OR REPLACE TABLE claim_details AS SELECT * FROM read_parquet(['claim_details.parquet']);Awesome, now the data is magically available in MotherDuck. Some of these datasets are pretty big and counting / selecting out of them happens as fast as it did for our thousand patient demo, except now across millions of patients.
Connecting in Hashboard to MotherDuck
To connect to MotherDuck, copy your service token from your settings in MotherDuck and paste it into the service token field for the MotherDuck connection option. Make sure you name the connection ‘motherduck-demo’ here:
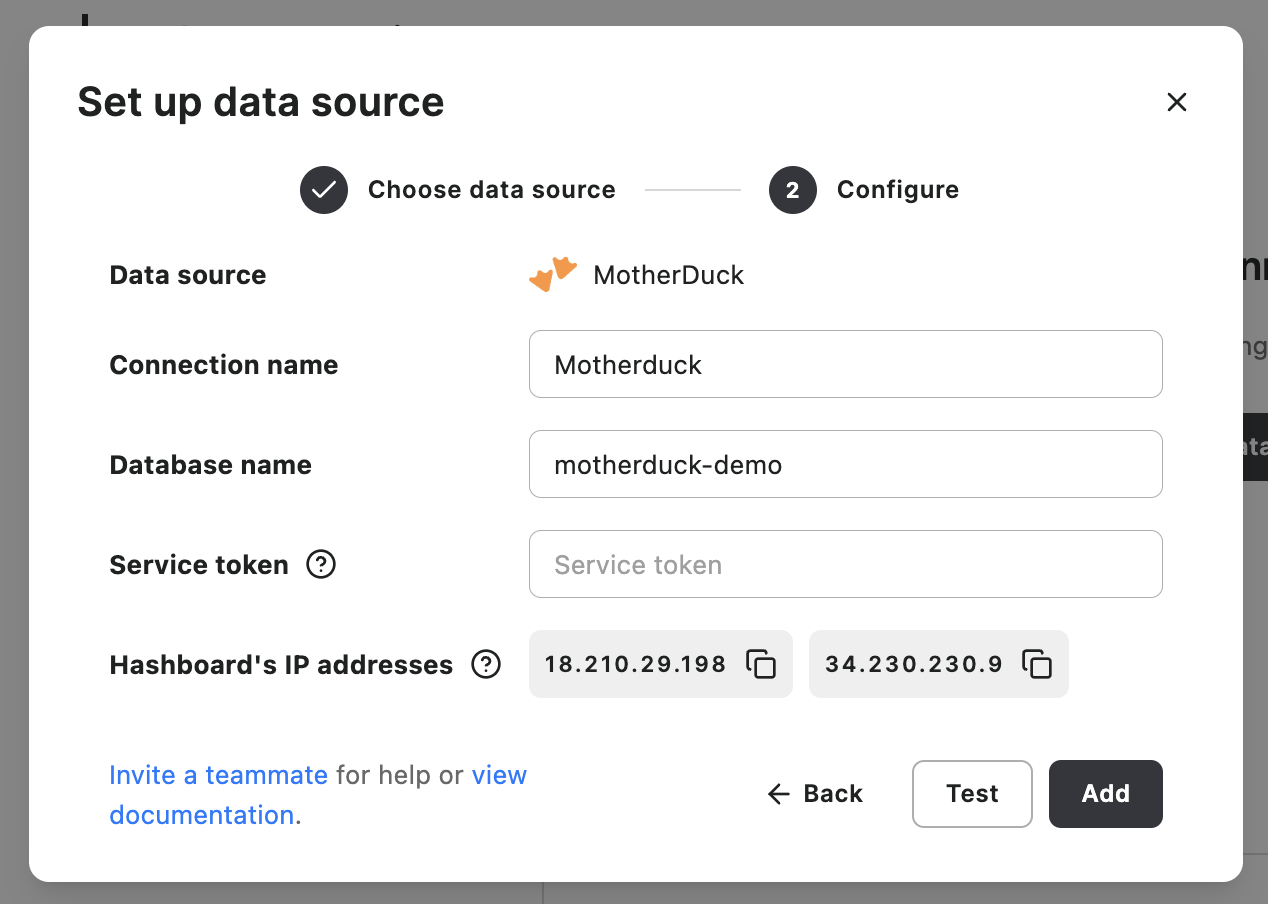 You can now deploy the Hashboard resources with our command line tool:
You can now deploy the Hashboard resources with our command line tool:
# if you’re not already signed up you can just run
hb signup
# now you can run deploy to deploy the configs in the example repo
hb deployHere’s our core claims data model which references our data in MotherDuck in github.
Explore data with Hashboard
Now we’re ready to start cutting and slicing our data in Hashboard! This entire visual explorer was built out through the code above without any additional config needed.