
So you want a data warehouse, but you don’t have a ton of time to get it all setup. If you’re on postgres and using GCP, AWS or heroku, we can get the infrastructure setup for your data warehouse in about 30 minutes. If you’re managing your own postgres database, the only part I won’t cover here is setting up your replica. I’ll just take you through setting up the pipes to get things started - then you can get started with the real work of analyzing and modeling your data :)
What we’ll cover:
Step 3: start analyzing and modeling
Step 5: (optional) visualize
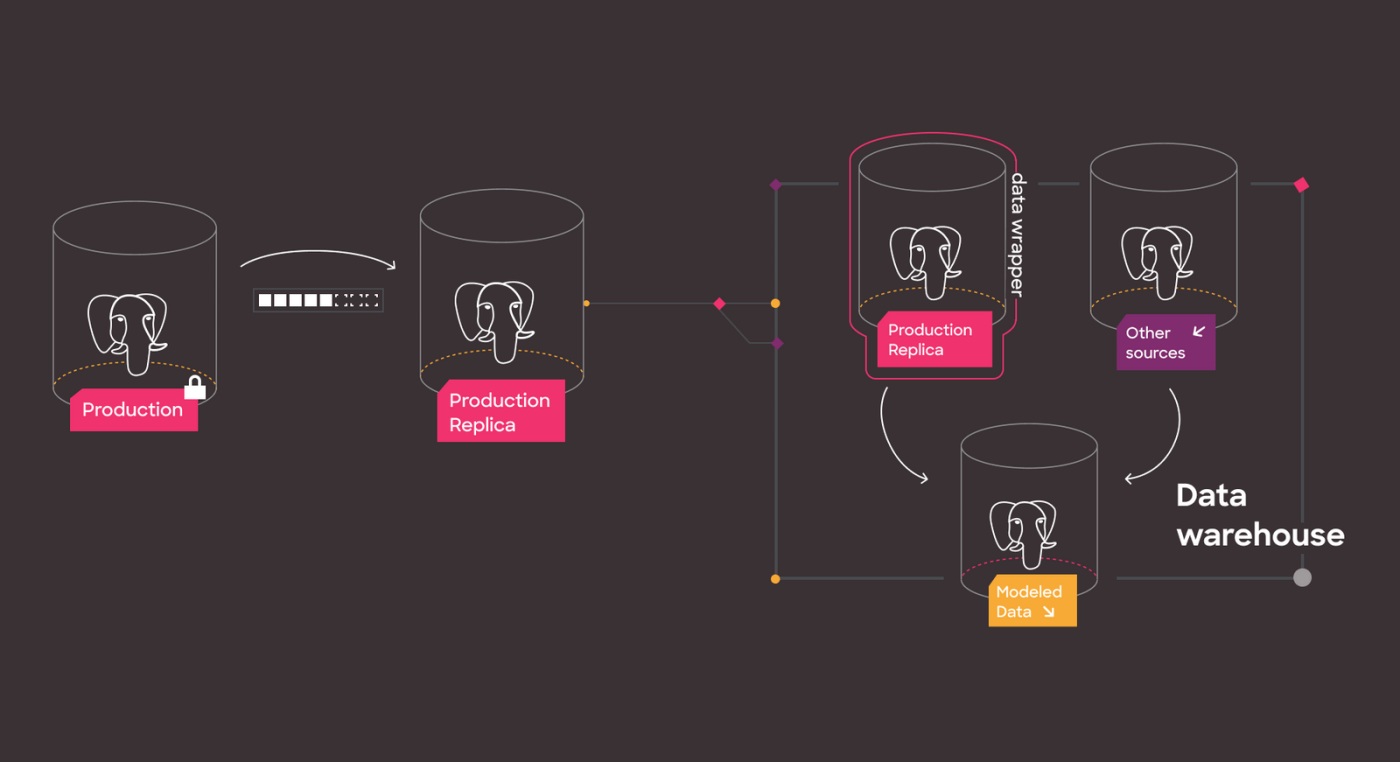
 Layout of what we'll cover in steps 1 through 4
Layout of what we'll cover in steps 1 through 4
What is a data warehouse and why is it useful?
A data warehouse is a database to hold consistent data representations of your business concepts. Having a single source of truth for important concepts will unlock your ability to start driving improvements in your business and help get consistent insights from your data. When everyone is just jamming on random production SQL queries - things are going to get confusing and your organization won’t have a shared vocabulary about what is going on. It’s like having ten versions of a spreadsheet. Should I be looking at customers or customers_final_v3.xls? Except worse because everyone is just looking at different cuts of the same sql queries.
Good things about a data warehouse strategy:
Safely query your data: separates analytics queries from your production database. A data warehouse is in a separate database than your application database, so you can hammer on it with complex queries and don’t worry about interfering with production systems.
Model your data for analytics: a data warehouse allows you to come up with standard views of data so that you can make future analytics queries consistent and easy. This process of creating derivative, canonical views is called data modeling. Maybe product information or clinical patient information is scattered across 10 different tables that you query in a similar way over and over again. In your data warehouse, you are going to create one consistent table (or view) to represent patients, or orders or whatever you want to analyze over and over again. Tools like dbt, or even just scheduled queries can help you maintain your consistent views.
Combine disparate datasets: a data warehouse strategy allows you to have a common place to start syncing data from other tools. Maybe your accounting, crm or marketing systems
When is a Postgres data warehouse a bad idea?
Okay, so building a data warehouse in postgres might not be a great idea. If you expect to have tens or hundreds of millions of objects / events / users to analyze pretty soon, I would invest in a more scalable solution, like BigQuery or Snowflake.
See step 4 for some ideas on ways to pretty easily implement BigQuery or Snowflake. I personally love BigQuery and recommend it most of the time: it’s really easy to manage and has a powerful sql dialect. But sometimes, you just have data in a production postgres database and you want to start analyzing it quickly. This guide is for the scrappy founder / PM / engineer trying to hack something together quickly.
Step 1: replicate your data
Allows you to safely query your data
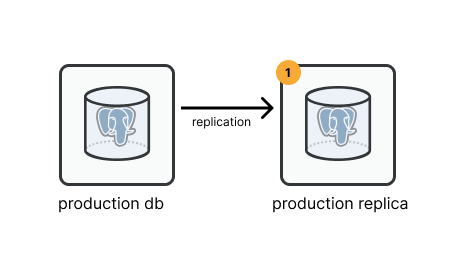
Step 1: create a database replica
You shouldn’t analyze data in your application’s database directly because you might write a bad query that uses all of the database’s resources. If you know what your doing and you don’t have any customers yet - this might be okay. But if you’re analyzing data, it’s likely you do have customers. Also, it’s really easy to mitigate this risk by creating a replica of your production data.
The first step to setting up your postgres data warehouse is to create a read-only replica of your application database. Streaming replication will copy your data more or less in realtime to a different database, which means the new replicated data will be safe to query without impacting your original db server.
If you’re using AWS Relational Database Service (like I am in this tutorial) - see the AWS instructions, GCP and heroku have equivalently easy steps for setting up a replica.
Let me know if it’s helpful to list instructions for self-managed streaming replication, it’s a bit less magic / straightforward than the rest of this guide.
Step 2: create data warehouse and add foreign data wrappers
Allows you to mutate / change data and create models
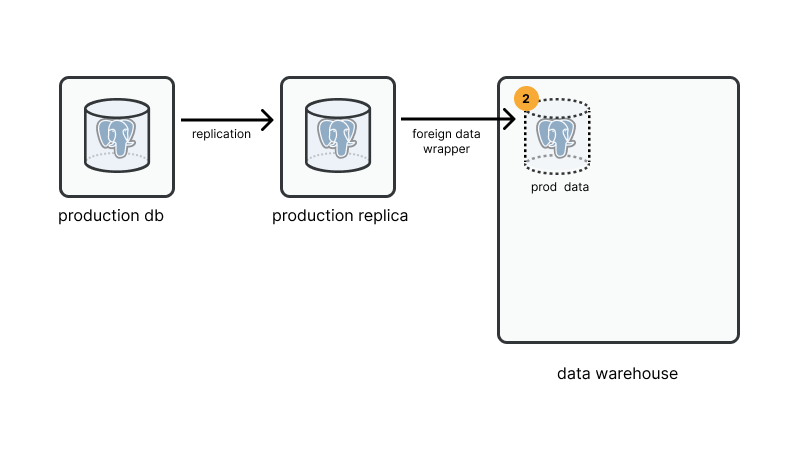
Step 2: creating a new database - getting prod data in there
So now you can safely query data. But we want to be able to write data as well. There are two instances where we may want to write data:
We want to write data so we can create new, cleaned up versions of data with CREATE TABLE and CREATE VIEW statements.
We want to import and write data from other systems, like our CRM, from segment or from marketing tools into our data warehouse.
First step here is we are going to create a second and final database which we’ll call data_warehouse. This will require you to create a new database in AWS RDS or GCP etc.
Our new database is going to have three schemas that we’re going to create for three distinct purposes over the next few steps of this guide:
production_replica_fdw: just below we’ll create this new schema and populate it with the data from production.
analytics: we’ll create tables and views for analytics here - this is where the action will happen in step 3.
source_data: we’ll drop some new sources here like crm data in step 4 later on
In order to get our production data into our postgres data warehouse we’ll use a magical extension in postgres called Foreign Data Wrappers (fdw). Foreign Data Wrappers create virtualized resources inside of your database that allow you to query data outside of your database directly with normal sql syntax. ✨magic✨ - this is a pretty flexible and cool feature, in this case we’re going to simply use fdw to query our replicated postgres data.
Set up Foreign Data Wrapper to get prod data:
Step 3: model your data with scripts or dbt
Allows you to mutate / change data and create models
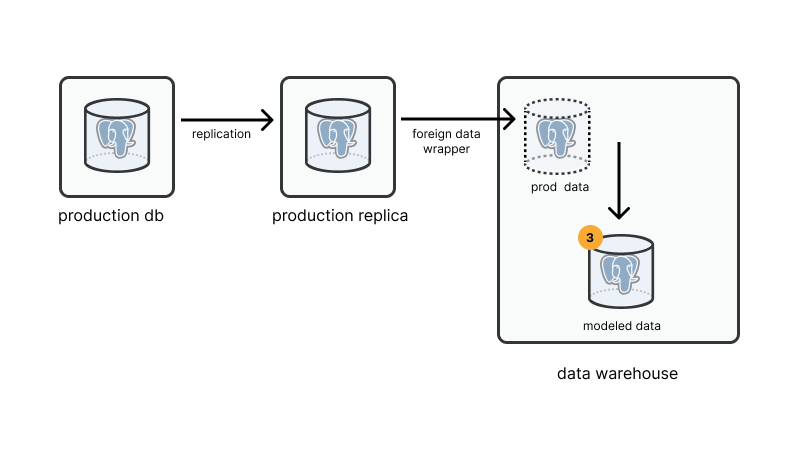
Step 3: create a new schema where you can modify data
Final step here now that we have production Postgres setup is to start creating some analytics resources for my org inside the data_warehouse machine. We’ll create our analytics schema and start building out some analytics tables and views:
Step 4: integrate other data sources
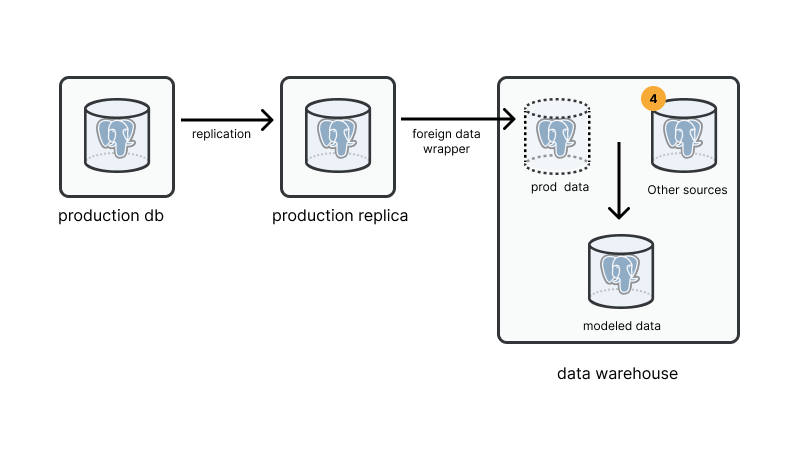
Step 4: get some more data from other systems
So we have our application data in our warehouse, but what about all the other tools that are collecting important marketing, sales and other domain data.
The way most people do this now is with an “ELT” strategy or an Extract and Load strategy (followed by Transforming the data later in the warehouse). So you’re going to just extract and load data into postgres without manipulating it. In the good old days (say five to ten years ago) it was more common to filter data and clean it up before putting it into the data warehouse to avoid data duplication and reduce the footprint in the warehouse. Since databases have gotten more scalable and faster - people have just started copying data exactly from other systems to make the transport code easier to reason about.
There are a few different services that will sync data for you so you don’t have to worry about it. For this demo we’ll use Airbyte - since they have a free-to-start service that you can sign up for. Fivetran and Stitch are two other commonly used cloud services. Two free / open source tools: Airbyte also has an open source version and Meltano is another open source tool.
Now go through the Airbyte onboarding: specify your data warehouse credentials.
A couple thoughts here:
Since we’re just using postgres here, there is a limit to the scalability assumption of an ELT strategy here.
Since we’re going to use a service like airbyte or fivetran anyways, it may be worth just setting up your postgres database as a source and transferring it into bigquery.
Step 5: visualize your data
Once you’ve standardized some of your data you’ll probably want to start visualizing it as well. Hashboard helps you visualize data in a consistent way by developing data models. There are also cheap tools like Looker Studio that can get you up and running quickly.